古人云:天下文章一大抄。整个三月,浙江大学 CS 开题报告热火朝天,其中各种纠结与不解、各种困惑与混乱、各种 Word/TeX 模版纷争,不再详述。23 号提交论文,但时至此刻,我刚刚 Google Translate 了一片水文搞定了外文翻译,修改了学院 bug 百出的 LaTeX 模版,搞定了开题报告的格式,至于剩下的 3500 字,尚无着落,痛苦不堪,心慌也。
废话少说,今天晚上去万方数据库校内镜像下载学位论文,岂知万方这个财主极其抠门猥琐,不但很多有价值的学术论文无法下载,可以下载的论文也是一个 zip 压缩包,然后里面几十到上百个 PDF 不等……看一篇完整的学位论文要打开几十个 PDF,莫说是我,就是我的 x201i,也该累死了……
一个典型的万方学位论文 zip 压缩包目录结构如下:
lox >>> tree IPTV机顶盒 GUI 子系统的研究与实现
IPTV 机顶盒 GUI 子系统的研究与实现
├── default.htm
├── Images
│ ├── ball.gif
lox >>> tree -L 3 -p -N | grep '\[d'
└── [drwxrwxr-x] wanfang
├── [drwxrwxr-x] IPTV机顶盒 GUI 子系统的研究与实现
│ ├── [drwxrwxr-x] Images
│ └── [drwxrwxr-x] Paper
├── [drwxrwxr-x] Tools设计与实现
│ ├── [drwxrwxr-x] Images
│ ├── [drwxrwxr-x] Paper
├── [drwxrwxr-x] 基于 QtEmbedded 的图形用户界面移植
│ ├── [drwxrwxr-x] Images
│ ├── [drwxrwxr-x] Paper
├── [drwxrwxr-x] 基于嵌入式 Linux 智能手机 GUI 平台的研究与实现
│ ├── [drwxrwxr-x] Images
│ ├── [drwxrwxr-x] Paper
├── [drwxrwxr-x] 基于消息通信机制嵌入式 GUI 的研究与实现
│ ├── [drwxrwxr-x] Images
│ ├── [drwxrwxr-x] Paper
├── [drwxrwxr-x] 嵌入式 Linux 图形用户界面的研究与开发
│ ├── [drwxrwxr-x] Images
│ ├── [drwxrwxr-x] Paper
├── [drwxrwxr-x] 嵌入式 uGUI 的研究与实现
│ ├── [drwxrwxr-x] Images
│ ├── [drwxrwxr-x] Paper
├── [drwxrwxr-x] 嵌入式系统轻量化 GUI 框架的设计与实现
│ ├── [drwxrwxr-x] Images
│ ├── [drwxrwxr-x] Paper
└── [drwxrwxr-x] 面向数字家电产品的 GUI 框架的设计与实现
├── [drwxrwxr-x] Images
├── [drwxrwxr-x] Paper
│ ├── bg.gif
│ ├── folder.gif
│ ├── H.gif
│ ├── I.gif
│ ├── L.gif
│ ├── nfolder.gif
│ ├── ofolder.gif
lox >>> tree IPTV机顶盒 GUI 子系统的研究与实现
IPTV 机顶盒 GUI 子系统的研究与实现
├── default.htm
├── Images
│ ├── ball.gif
│ ├── bg.gif
│ ├── folder.gif
│ ├── H.gif
│ ├── I.gif
│ ├── L.gif
│ ├── nfolder.gif
│ ├── ofolder.gif
│ └── T.gif
└── Paper
└── pdf
├── d0447950001.pdf
├── d0447950002.pdf
├── d0447950003.pdf
├── d0447950004.pdf
├── d0447950005.pdf
├── d0447950006.pdf
├── d0447950007.pdf
├── d0447950008.pdf
├── d0447950009.pdf
├── d044795wz.pdf
├── d044795zye.pdf
├── fm.htm
├── index.htm
├── iptv.pdf
├── left.htm
├── ml.htm
└── single_merged_pdf.pdf
3 directories, 28 files
所有的 PDF 文档在 ./Paper/pdf 目录下,并且必有一个 xxxxwz.pdf 和一个 xxxxzye.pdf 文件,剩下的 PDF 文件基本上内容顺序和编号顺序一致,但是不排除有页码重叠的状况。
想到的办法就是找 CLI 工具,将这些 PDF 合并成一份完整的论文。Arch Linux 下: pacman -Ss pdf ,结合 Google,得到几个相关的 PDF 工具:
- pdfedit
- ghostscript
- pdftk
- poppler
PDFedit 是图形化的 PDF edit(编辑)工具,显然不符合 CLI 自动化处理的要求。而且看界面是基于 Qt 3.x 的,编辑功能应该是很强大的。具体可以看 PDFedit 的 Screenshots。不过这与本文无关了。
ghostscript is an interpreter for the PostScript language。linuxtoy 给出了一种合并 PDF 方法,我尝试了一下,但是万方本身的 PDF 是加密的,直接转换会出现莫名其妙的错误,所以这种方法最终失败。
PDFtk 是一个十分强大的 PDF 工具,按照官方的说法,PDFtk 可以用来:
- Merge PDF Documents
- Split PDF Pages into a New Document
- Rotate PDF Pages or Documents
- Decrypt Input as Necessary (Password Required)
- Encrypt Output as Desired
- Fill PDF Forms with FDF Data or XFDF Data and/or Flatten Forms
- Apply a Background Watermark or a Foreground Stamp
- Report on PDF Metrics such as Metadata, Bookmarks, and Page Labels
- Update PDF Metadata
- Attach Files to PDF Pages or the PDF Document
- Unpack PDF Attachments
- Burst a PDF Document into Single Pages
- Uncompress and Re-Compress Page Streams
- Repair Corrupted PDF (Where Possible)
可以用 pdftk 1.pdf 2.pdf 3.pdf && cat output 123.pdf 的方式来合并 PDF,但是由于万方 PDF 的特殊加密,用 PDFtk 合并时,会出现 "OWNER PASSWORD REQUIRED" 的失败提示。所以成功合并 PDF 的最关键问题就是去掉万方 PDF 加密。
幸运的是,我在 townx 找到了解决方法,感谢万能的 Google。剩下的任务,就是 shell script 的天地了。
至于 shell Script,已经好久没有摆弄,很多写法已经生疏,好在半年前在华数淘宝写的脚本还在,打开浏览了下,照葫芦画瓢,倒也没有遇到太大困难。完整的脚本如下:
#!/usr/bin/env bash
################################################################################
# Purpose: Merge pdf file downloaded from Wanfang dissertation database
# (http://g.wanfangdata.com.cn/)
# Author: Xiao Hanyu(xiaohanyu1988@gmail.com)
# Depends:
# pdftk: merge multiple pdf files, pdftk is also a useful pdf
# manipulation tools
# ps2pdf/pdftops: pdf --> ps then ps --> pdf to remove encryption
################################################################################
function usage
{
cat << EOF
`basename $0`: A utility to merge encryted pdf files into one single pdf
Usage: `basename $0` [Options]
Example:
`basename $0` -f "file1.pdf file2.pdf" -o merged.pdf
`basename $0` -d input_pdf_dir -o merged.pdf
`basename $0` -d input_pdf_dir
Options:
-f: set the input pdf file list
-d: set the input pdf directory
-o: set the output pdf filename
-h: show this help
EOF
}
function merge_pdfs
{
echo "######## Convert begin!! ########"
for pdf in $pdf_list
do
## do not use pdf_name = `basename $pdf .pdf`
## since basename will remove the directory prefix of $pdf
pdf_name=`echo $pdf | sed -e "s/\.pdf//"`
## add some animation ^_^
echo -n "$pdf_name.pdf ---->> $pdf_name.ps "
pdftops $pdf_name.pdf $pdf_name.ps
echo "---->> $pdf_name.pdf"
ps2pdf $pdf_name.ps $pdf_name.pdf
rm -rf $pdf_name.ps
done
echo "######## Convert end!! ########"
echo "######## Merge begin!! ########"
pdftk $pdf_list cat output $pdf_merge
echo "######## Merge success, open $pdf_merge to see the result. Bye!! ########"
}
while getopts "d:f:o:h" arg
do
case $arg in
d)
pdf_dir=$OPTARG
pdf_list=`ls $pdf_dir/*pdf`
;;
f)
pdf_list=$OPTARG
;;
o)
pdf_merge=$OPTARG
;;
h)
usage
exit 0
;;
?)
echo "!!Wrong command options"
usage
exit 1
;;
esac
done
# if pdf_dir is not set yet, then it's set to default(that is, current directory)
pdf_dir=${pdf_dir:-"."}
# set default output pdf filename, plus $pdf_dir prefix
pdf_merge="${pdf_dir}/${pdf_merge:-"single_merged_pdf.pdf"}"
merge_pdfs脚本结构还是很简单的:
- 参数解析采用 bash 内置的
getopts,暂时只支持短选项 - 有一个帮助说明函数
function usage{} - 关键函数是
function merge_pdfs{},尤其需要注意目录名和文件名的处理
调用方法如 function usage{} 里面所示:
./wanfang_pdf_merge.sh -d pdf_dir./wanfang_pdf_merge.sh -d . -o merged_pdf.pdf./wanfang_pdf_merge.sh -f "dir1/pdf1.pdf dir2/pdf2.pdf" -o output/merged_pdf.pdf
测试:

在这个基础脚本上进一步封装下,比如,对于如下的目录结构:
lox >>> tree -L 3 -p -N | grep '\[d'
└── [drwxrwxr-x] wanfang
├── [drwxrwxr-x] IPTV机顶盒 GUI 子系统的研究与实现
│ ├── [drwxrwxr-x] Images
│ └── [drwxrwxr-x] Paper
├── [drwxrwxr-x] Tools设计与实现
│ ├── [drwxrwxr-x] Images
│ ├── [drwxrwxr-x] Paper
├── [drwxrwxr-x] 基于 QtEmbedded 的图形用户界面移植
│ ├── [drwxrwxr-x] Images
│ ├── [drwxrwxr-x] Paper
├── [drwxrwxr-x] 基于嵌入式 Linux 智能手机 GUI 平台的研究与实现
│ ├── [drwxrwxr-x] Images
│ ├── [drwxrwxr-x] Paper
├── [drwxrwxr-x] 基于消息通信机制嵌入式 GUI 的研究与实现
│ ├── [drwxrwxr-x] Images
│ ├── [drwxrwxr-x] Paper
├── [drwxrwxr-x] 嵌入式 Linux 图形用户界面的研究与开发
│ ├── [drwxrwxr-x] Images
│ ├── [drwxrwxr-x] Paper
├── [drwxrwxr-x] 嵌入式 uGUI 的研究与实现
│ ├── [drwxrwxr-x] Images
│ ├── [drwxrwxr-x] Paper
├── [drwxrwxr-x] 嵌入式系统轻量化 GUI 框架的设计与实现
│ ├── [drwxrwxr-x] Images
│ ├── [drwxrwxr-x] Paper
└── [drwxrwxr-x] 面向数字家电产品的 GUI 框架的设计与实现
├── [drwxrwxr-x] Images
├── [drwxrwxr-x] Paper
我们的封装脚本命令如下:
for pdf_dir in `tree wanfang -ipNf | grep '\[d' | grep 'pdf' | awk '{print $2}'`
do
~/tools/wanfang_pdf_merge.sh -d $pdf_dir
done接下来喝咖啡!!!
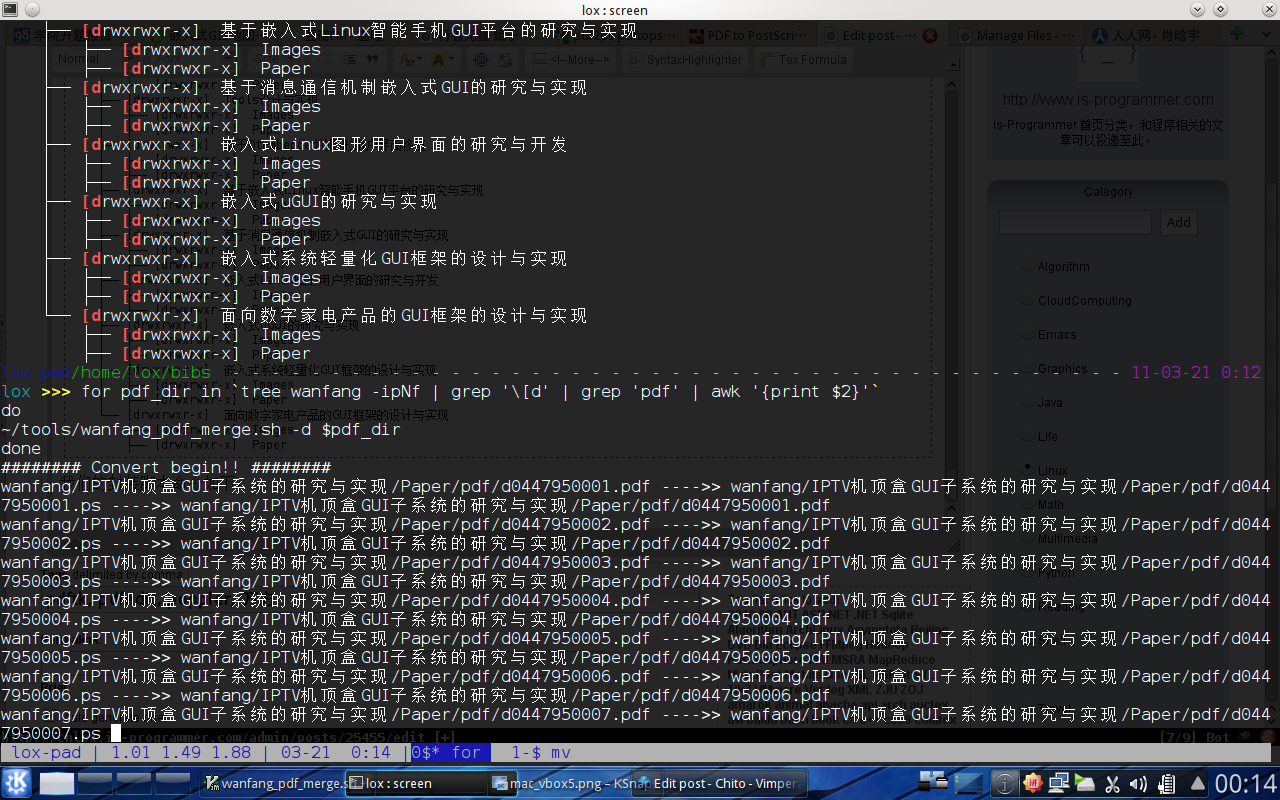
咖啡喝完后,我们来看一下结果:
lox >>> tree -ipNf | grep 'single'
[-rw-rw-r--] ./wanfang/IPTV机顶盒 GUI 子系统的研究与实现/Paper/pdf/single_merged_pdf.pdf
[-rw-rw-r--] ./wanfang/Tools 设计与实现/Paper/pdf/single_merged_pdf.pdf
[-rw-rw-r--] ./wanfang/Tools 设计与实现/Paper/pdf/single_merged_pdf.ps
[-rw-rw-r--] ./wanfang/基于 QtEmbedded 的图形用户界面移植/Paper/pdf/single_merged_pdf.pdf
[-rw-rw-r--] ./wanfang/基于嵌入式 Linux 智能手机 GUI 平台的研究与实现/Paper/pdf/single_merged_pdf.pdf
[-rw-rw-r--] ./wanfang/基于消息通信机制嵌入式 GUI 的研究与实现/Paper/pdf/single_merged_pdf.pdf
[-rw-rw-r--] ./wanfang/嵌入式 Linux 图形用户界面的研究与开发/Paper/pdf/single_merged_pdf.pdf
[-rw-rw-r--] ./wanfang/嵌入式 uGUI 的研究与实现/Paper/pdf/single_merged_pdf.pdf
[-rw-rw-r--] ./wanfang/嵌入式系统轻量化 GUI 框架的设计与实现/Paper/pdf/single_merged_pdf.pdf
[-rw-rw-r--] ./wanfang/面向数字家电产品的 GUI 框架的设计与实现/Paper/pdf/single_merged_pdf.pdf
大功告成!!!
接下来的任务是:
写论文!!!!!!!!!!